The National Research Platform (NRP) (nationalresearchplatform.org) is a partnership of more than 50 institutions, led by researchers and cyberinfrastructure professionals at UC San Diego, supported in part by awards from the National Science Foundation.
NRP is the name of the set of programs, facilities, and policies that are designed for distributed growth and expansion. NRP’s primary computation, storage, and network resource is a ~300 node distributed cluster called Nautilus that will grow significantly by the end of 2022. Nautilus hosts many network testing data transfer nodes including ones used by the Open Science Grid (OSG).
Nautilus is a powerful nationally distributed computer system with CPUs, GPUs, and FPGAs, in two types of subsystems (“high-performance FP64/FPGA” and “FP32-optimized”), specialized for a wide range of data science, simulations, and machine learning or artificial intelligence, allowing data access through a federated national-scale content delivery network.
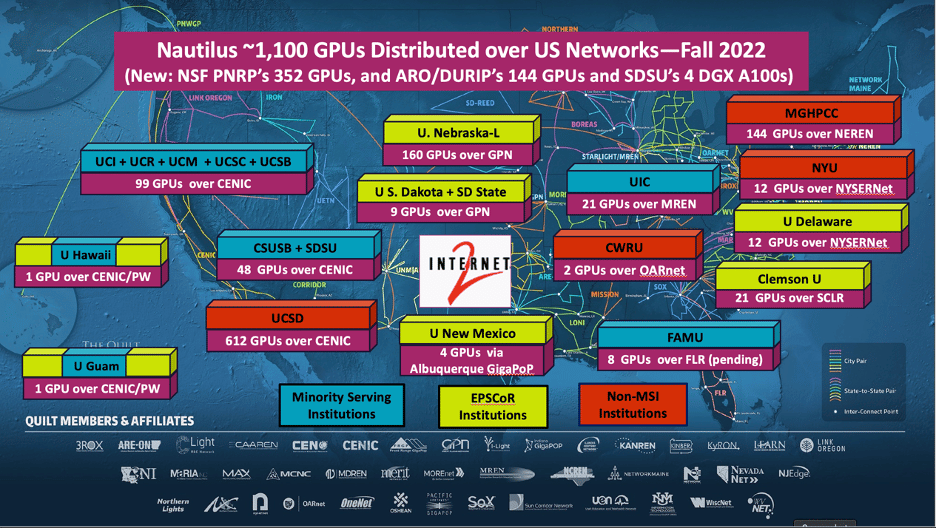
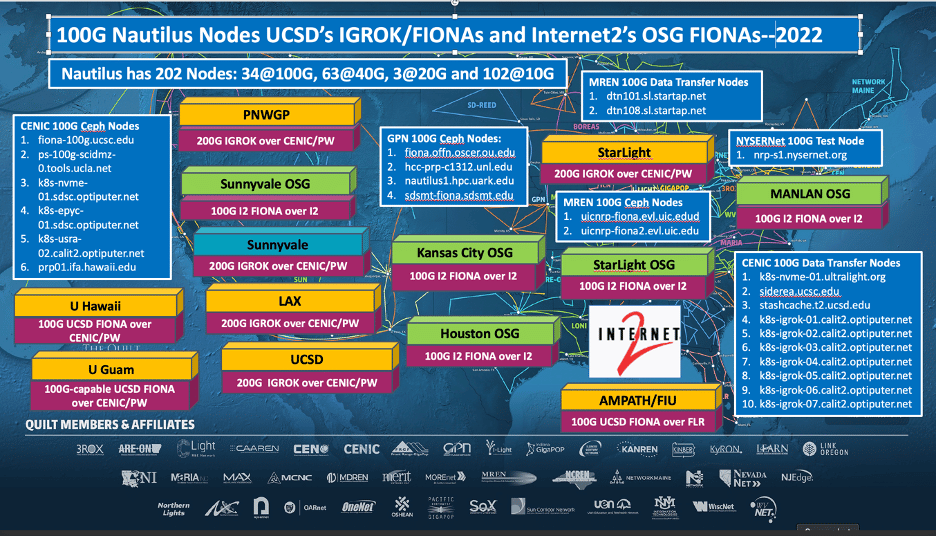
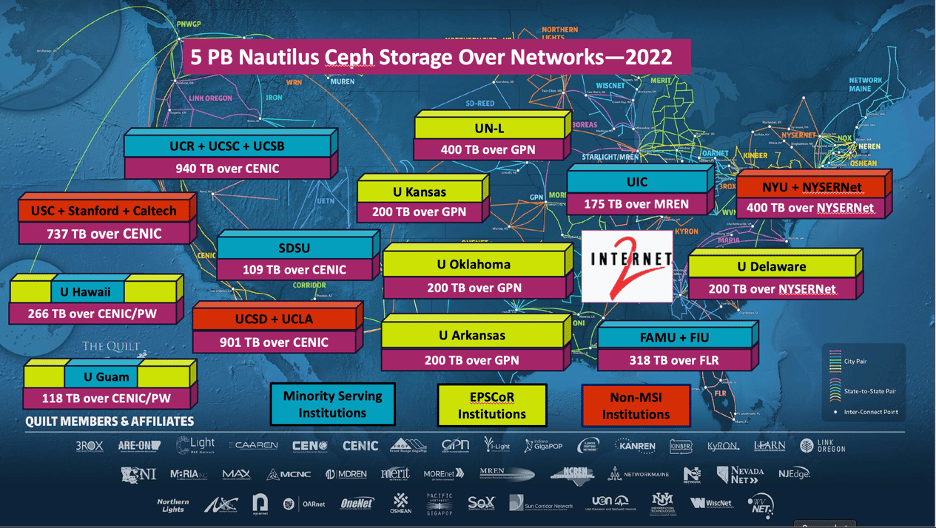
The PNRP award (NSF#2112167, Frank Würthwein, PI) has written into its project plan that it will operate a Kubernetes cluster and be available for others to join. PNRP has a lifetime of potentially 10-12 years including operations support. The PRNP adds 288 GPUs in Fall 2022 to Nautilus at UN-L and MGHPCC and a composable cluster of 32 ALVEO FPGAs, 64 FP64 GPUs, CPUs, and storage at UCSD’s San Diego Supercomputer Center (SDSC).
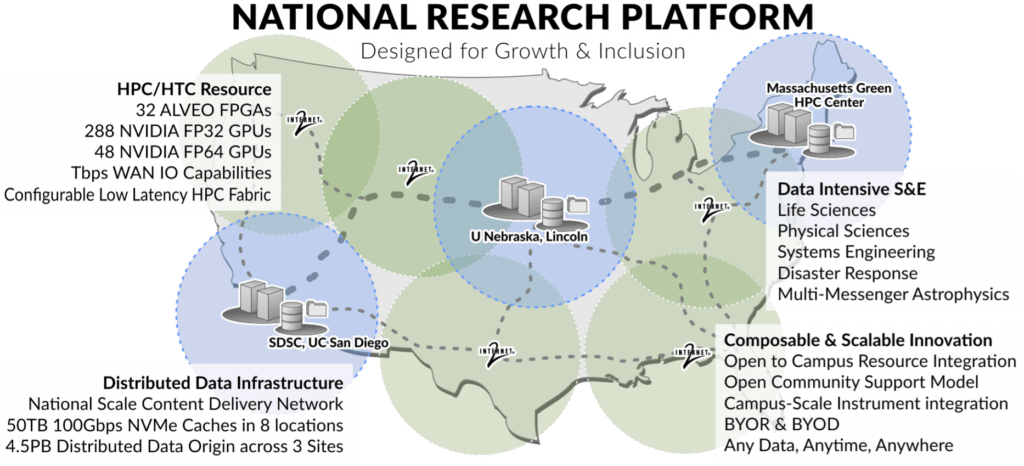
The UN-Lincoln Holland Computing Center (Derek Weitzel, subcontract PI) is responsible for the day-to-day operations of Nautilus Kubernetes clusters. The development environments for R&D are led by SDSC.
SDSC will add the PNRP award-paid hardware to the NSF ACCESS allocation process after the initial period. There will also be many nodes (called “bring your own resources” (BYOR) hardware) joined or federated into Nautilus hardware not bought by PRNP, now and over the next 10 years. The ACCESS users will get guaranteed cycles: Nautilus can fence off any specific hardware for exclusive access for any amount of time needed–it only takes minutes and can be user-initiated. The BYOR hardware not bought by PRNP in Nautilus will then be governed by the existing Nautilus policies, as separate from ACCESS policies.
A Slack-like collaboration platform called “Matrix” is available and currently has hundreds of users (see nationalresearchplatform.org to join).
Some credits: The central PRP concept of networking and exploiting the NSF-funded DMZs was Larry Smarr’s and Phil Papadopoulos’s. Nautilus is John Graham’s name for the distribute Kubernetes cluster he designed; John and Dima Mishin were our early adopters of Kubernetes, Ceph and Matrix. The emphasis on using 32-bit GPUs for AL/ML and Computational Media is Tom DeFanti’s and it was nurtured by John and Dima. Frank brought in the Open Science Grid and now, the PNRP award. Of course, many others contributed to infrastructure designs and implementations over the last 20 years starting with the NSF-funded OptIPuter project in 2002. CENIC, California’s R&E Network, Internet2, the Great Plains Network, NYSERnet. MREN/StarLight have been the key infrastructure linking universities, national labs, regional networks throughout the US and national research networks in other countries.
There will be a Fourth National Research Platform (4NRP) Workshop February 8-10, 2023 at UC San Diego.
Nautilus from a User’s Point of View
Most of Nautilus’ 600 GPUs to date are FP32 (single precision floating point) video game GPUs. The PRNP FP32 GPUs are all data center GPUs. All the CPUs and GPUs do FP64, of course, but they much, much slower than the more expensive FP64 GPUs. PRNP also is installing a large composable cluster with CPUs, FP64 GPUs and FPGAs at SDSC, shown in the PRNP diagram above.
A fundamental concept of Nautilus is containerization (as in Docker) of application codes. Many campuses have Research IT cyberinfrastructure professionals to help containerize code and optimize it.
To get started on NRP/Nautilus, users go to https://nationalresearchplatform.org/ and start at join/contact. There are JupyterLab notebooks available that address certain classes of need and reduce the pain of getting started a lot, if they do what is needed. They may need to get a cyberinfrastructure professional programmer to assist. Our goal is to have people self-onboard, and it usually works with determination. As noted above, Matrix is the online chat room we run; the developers, cyberinfrastructure professionals, and sysadmins prefer to monitor Matrix rather than e-mail.
Nautilus users don’t usually need to know where they are computing. We have developed regions (Western, Central, Northeastern, Asia-Pacific) of storage pools called Ceph Pools. They are in regions for speed of light response reasons; and users can designate if they want to compute in the region their data is stored in. This can avoid a lot of downloading to local storage if done correctly and the Ceph Pools also encourage sharing data. They are working storage–we assume you have moved your data from archival sources or can recreate it. Nautilus does not provide managed research archival storage, although Supercomputer Centers offer such services as do the commercial clouds.
By design, Nautilus has decoupled the requirement of hosting compute/data resources from the researchers using them. We ask researchers to write technical papers which include giving NSF credit for providing Nautilus computing and storage. We also want campuses to share the burden of hosting nodes that our grants buy or the many 100s that others contribute. The cost of power and networking exceed the cost of the hardware over time so a single campus like UCSD simply cannot not be expected to host Nautilus nodes for everyone. Research faculty, of course, don’t pay for power and networking out of their grants, so they get to stretch their grant and startup funds, and our CapEx-based model generally fits research grants better than the OpEx model of clouds.
Some campuses want to help their researchers by hosting on-premises equipment this way, and some are moving primarily to commercial clouds and NSF ACCESS for their needs. However, for a small fraction of what a grad student costs a faculty member can add a 8 GPU node and get access to a huge amount of peak computing and disk space, what is called “Bring your own Resources (BYOR)” style. What faculty usually can’t afford to sustain is the sysadmin salary for a small Linux cluster they buy. We offer to do the sysadmin for such nodes.
Frank Würthwein observed:
Community cyberinfrastructure (CCI) like the NRP scales by providing more distributed hardware driven by the needs of researchers. It is motivated by three simple observations regarding compute capacity:
- CCI scales linearly with cost at any given time (that is, if you buy 2x more, you get 2x as much compute capability)
- CCI scales exponentially at fixed cost given time (that is, if you wait, the capability exponentiates)
- The human effort to support CCI scales roughly logarithmically with capacity given sufficient attention to automation (that is, adding nodes increases the need for system administrators’ time and effort only slightly, way less than linearly).
To perform the “logarithmic” sysadmin support, we need to remotely manage the nodes in Nautilus that are hosted in campus Science DMZs. We need to be able to update software quickly for Nautilus when patches are needed (all too often) and we use extremely automated techniques to update hundreds of nodes on Nautilus at once, keeping them in software sync. Other sites can federate with Nautilus and maintain 100% local control, if they prefer.
Nautilus and Kubernetes have a concept of equipment aging out and how that affects BYOR nodes. When a user’s BYOR node gets hung or drops dead, Kubernetes logically off-lines it and it is rebooted. If it doesn’t come up, it either gets fixed with local hands-on help or recycled. Some of our GPU nodes are 5 years old already and are approaching being not worth fixing.
Nautilus background mode delivers cycles very satisfactorily if the user code is checkpointed. The huge IceCube computations run this way and do not impact real-time users.
Nautilus’ regional Ceph Pools are for sharing and considered transient even if they are designed to be resilient to nodes going offline (which is due mostly to network disruptions). The Ceph Pool nodes are on 100G and 40G links and have M.2 NVMe buffers to provide ultra-fast transfers so the CPUs and GPUs aren’t waiting for data most of the time. This assumes of course that the task involves doing a lot of computing on the data once in GPU memory. Ceph nodes have been added by the Great Plains Network, and NYSERNet, for instance.
Nautilus has so far discouraged CPU-only jobs because most campus/NSF compute facilities serve that need very well, and Nautilus’ initial goal was and is still to serve under-served extreme users of FP32 computing who otherwise would have to request huge amounts of expensive FP64 resources. PNRP adds significant FP64 resources as well as FP32 nodes. Other institutions are welcomed to add FP64, FPGA, as well as FP32, and custom PyTorch/TensorFlow hardware, as is being done by UCSD, UCSB, SDSU, Case Western Reserve, Clemson, and others.
